How do search engines work?
- Crawl: Scour the Internet for content, looking over the code/content material for every URL they discover.
- Index: Store and organize the content determined all through the crawling method. Once a web page is within the index, it’s within the going for walks to be displayed as a end result to relevant queries.
3. Rank: Provide the pieces of content material in order to best answer a searcher’s question, which means that outcomes are ordered by way of most applicable to least relevant.

What is search engine crawling?
Crawling is the invention system in which search engines like google ship out a group of robots (called crawlers or spiders) to locate new and updated content. Content can range — it is able to be a website, an photo, a video, a PDF, etc. — however irrespective of the layout, content is observed via hyperlinks.

Googlebot starts out by fetching some net pages, after which follows the links on those webpages to find new URLs. By hopping along this route of links, the crawler is capable of discover new content and add it to their index known as Caffeine — a massive database of determined URLs — to later be retrieved when a searcher is looking for facts that the content material on that URL is a good fit for.
What is a search engine index?
Search engines method and shop statistics they locate in an index, a massive database of all the content material they’ve determined and deem properly enough to serve as much as searchers.

Search engine ranking
When someone plays a seek, search engines like google scour their index for enormously relevant content after which orders that content material inside the hopes of fixing the searcher’s query. This ordering of seek outcomes by means of relevance is referred to as ranking. In widespread, you could expect that the better a website is ranked, the more relevant the hunt engine believes that web page is to the query.

It’s feasible to block search engine crawlers from element or all of your web site, or educate serps to keep away from storing certain pages of their index. While there can be reasons for doing this, if you need your content determined by using searchers, you need to first make certain it’s accessible to crawlers and is indexable. Otherwise, it’s as good as invisible.
In SEO, not all search engines are equal
Many beginners surprise about the relative importance of precise engines like google. Most human beings understand that Google has the biggest market percentage, but how important it’s miles to optimize for Bing, Yahoo, and others? The fact is that regardless of the lifestyles of extra than 30 major internet search engines, the SEO network simply simplest can pay interest to Google. Why? The brief solution is that Google is wherein the substantial majority of humans search the internet. If we include Google Images, Google Maps, and YouTube (a Google assets), greater than ninety% of internet searches manifest on Google — that’s nearly 20 instances Bing and Yahoo combined.

Crawling: Can search engines find your pages?
As you have just learned, making sure your web site receives crawled and indexed is a prerequisite to showing up within the SERPs. If you already have a website, it might be a good idea to start off by way of seeing how a lot of your pages are inside the index. This will yield some terrific insights into whether or not Google is crawling and finding all the pages you want it to, and none which you don’t.
One manner to check your indexed pages is “site:yourdomain.Com”, a complicated search operator. Head to Google and type “web site:yourdomain.Com” into the hunt bar. This will return results Google has in its index for the web site targeted:
Robots.txt
Robots.Txt documents are placed within the root listing of websites (ex. Yourdomain.Com/robots.Txt) and advise which elements of your web site serps must and should not crawl, as well as the speed at which they move slowly your site, thru precise robots.Txt directives.

How Googlebot treats robots.txt files
If Googlebot cannot find a robots.Txt file for a website, it proceeds to move slowly the website.
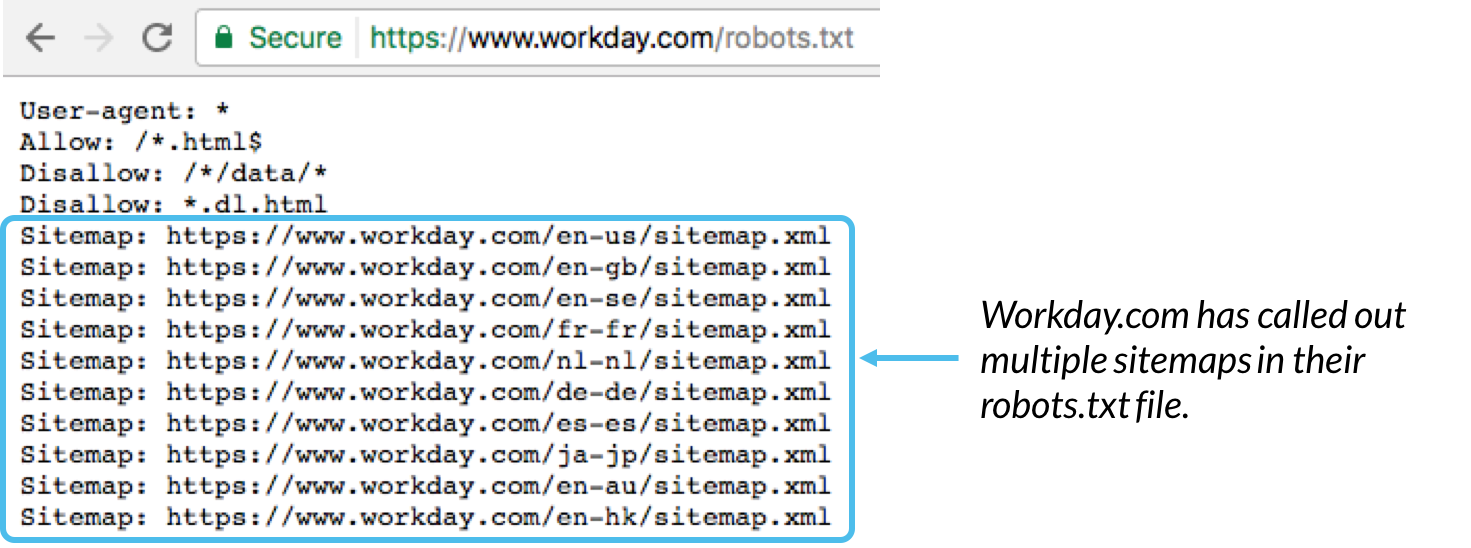
If Googlebot unearths a robots.Txt record for a website, it’ll typically abide by means of the pointers and proceed to crawl the website online.
If Googlebot encounters an error while trying to access a site’s robots.Txt document and cannot determine if one exists or not, it might not move slowly the website.
Defining URL parameters in GSC
Some web sites (most common with e-commerce) make the equal content available on multiple one of a kind URLs via appending certain parameters to URLs. If you’ve ever shopped on-line, you’ve likely narrowed down your search via filters. For instance, you may search for “footwear” on Amazon, after which refine your search via length, color, and style. Each time you refine, the URL adjustments barely:

How does Google realize which model of the URL to serve to searchers? Google does a quite excellent task at identifying the representative URL on its very own, however you could use the URL Parameters feature in Google Search Console to inform Google precisely the way you need them to deal with your pages. If you use this option to inform Googlebot “move slowly no URLs with ____ parameter,” you then’re basically asking to cover this content material from Googlebot, which could result in the removal of those pages from seek consequences. That’s what you need if those parameters create duplicate pages, but not perfect in case you need those pages to be listed.
Can crawlers find all your important content?
Now which you understand a few methods for making sure search engine crawlers live far from your unimportant content material, allows find out about the optimizations that can assist Googlebot find your important pages.

Sometimes a seek engine can be capable of locate elements of your web page by using crawling, however different pages or sections might be obscured for one reason or another. It’s vital to make certain that search engines like google and yahoo are able to find out all of the content you need listed, and not simply your homepage.
Common navigation mistakes that can keep crawlers from seeing your entire site:
Having a cell navigation that suggests extraordinary outcomes than your computing device navigation
Any sort of navigation where the menu gadgets aren’t in the HTML, such as JavaScript-enabled navigations. Google has gotten plenty better at crawling and know-how JavaScript; however it’s nevertheless no longer an excellent process. The more surefire manner to ensure something receives discovered, understood, and indexed by way of Google is by way of setting it inside the HTML.
Personalization, or showing particular navigation to a particular type of vacationer versus others, could seem like cloaking to a seek engine crawler
Forgetting to hyperlink to a primary page in your website through your navigation — remember, links are the paths crawlers follow to new pages!
Do you have clean information architecture?
Information architecture is the practice of organizing and labeling content on a internet site to enhance performance and fundability for users. The excellent facts architecture is intuitive, meaning that users should not should assume very hard to float via your internet site or to discover something.

Are you utilizing sitemaps?
A sitemap is simply what it appears like: a listing of URLs for your site that crawlers can use to discover and index your content material. One of the easiest ways to make sure Google is locating your maximum priority pages is to create a record that meets Google’s requirements and submit it via Google Search Console. While submitting a sitemap doesn’t replace the want for appropriate web page navigation, it is able to simply help crawlers follow a path to all your crucial pages.
Are crawlers getting errors when they try to access your URLs?
In the procedure of crawling the URLs on your web site, a crawler can also stumble upon errors. You can go to Google Search Console’s “Crawl Errors” document to stumble on URLs on which this is probably going on – this file will show you server errors and no longer observed errors. Server log documents also can display you this, as well as a treasure trove of different facts which includes crawl frequency, however because getting access to and dissecting server log files is a extra advanced tactic, we gained’t talk it at length in the Beginner’s Guide, even though you can examine greater approximately it here.
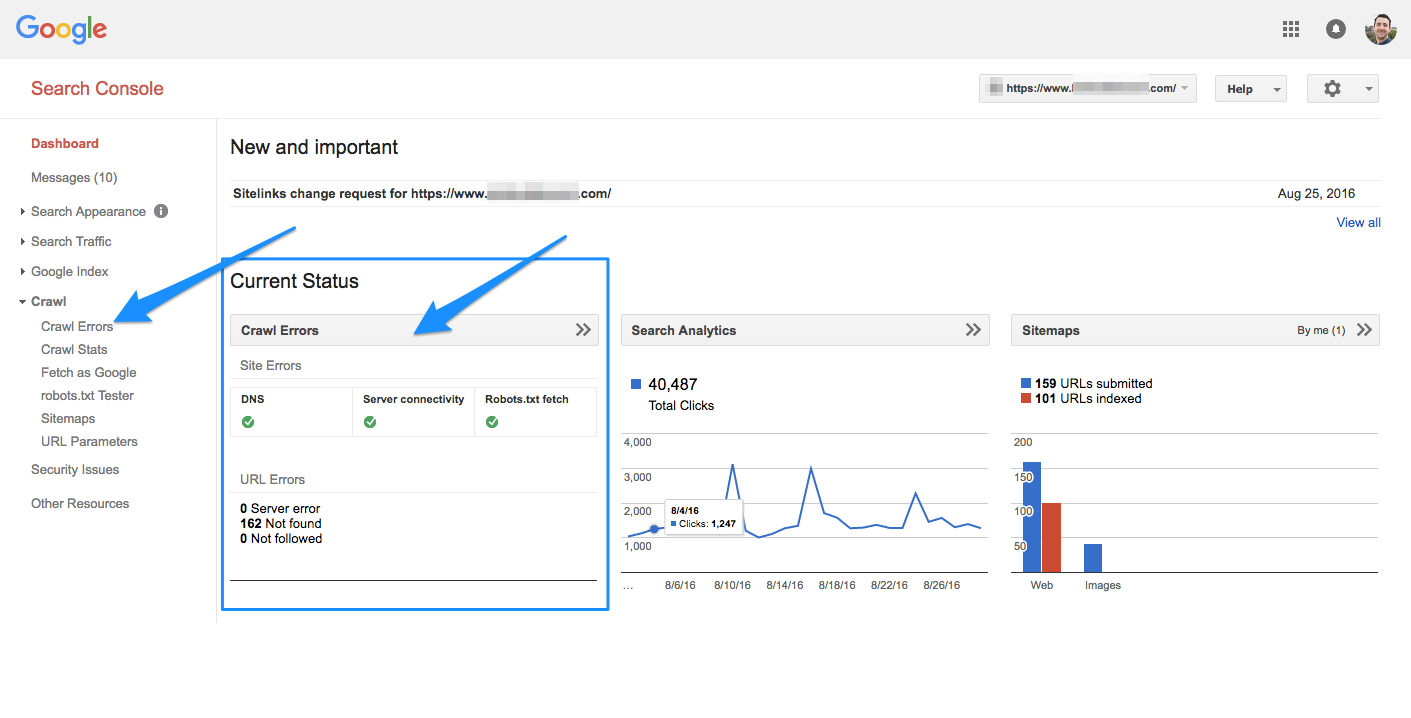
Before you can do whatever significant with the crawl mistakes file, it’s important to understand server errors and “now not observed” errors.
Indexing: How do search engines interpret and store your pages?
Once you’ve ensured your site has been crawled, the next order of business is to ensure it can be listed. That’s proper — just due to the fact your website can be discovered and crawled via a search engine doesn’t necessarily mean that it will be saved of their index. In the preceding phase on crawling, we discussed how engines like google find out your web pages. The index is in which your determined pages are stored. After a crawler unearths a web page, the hunt engine renders it much like a browser might. In the technique of doing so, the search engine analyzes that web page’s contents. All of that facts is saved in its index.

Can I see how a Googlebot crawler sees my pages?
Yes, the cached version of your web page will mirror a snapshot of the closing time Googlebot crawled it.
Google crawls and caches internet pages at one-of-a-kind frequencies. More installed, well-known web sites that submit often like https://www.Nytimes.Com will be crawled more often than the a lot-much less-well-known internet site for Roger the Mozbot’s side hustle, http://www.Rogerlovescupcakes.Com (if handiest it had been actual…)
You can view what your cached model of a page looks as if through clicking the drop-down arrow subsequent to the URL in the SERP and choosing “Cached”:
Ranking: How do search engines rank URLs?
How do serps make sure that once someone sorts a query into the search bar, they get relevant results in return? That technique is called ranking, or the ordering of seek effects by using maximum relevant to least applicable to a specific query.
To determine relevance, search engines like google use algorithms, a technique or formulation by way of which stored records is retrieved and ordered in meaningful ways. These algorithms have long gone through many adjustments through the years so that you can enhance the satisfactory of seek outcomes. Google, for example, makes set of rules modifications every day — some of those updates are minor pleasant tweaks, whereas others are center/broad set of rules updates deployed to tackle a particular difficulty, like Penguin to tackle hyperlink unsolicited mail.
The role links play in SEO
When we talk approximately hyperlinks, we ought to imply two matters. Backlinks or “inbound hyperlinks” are hyperlinks from other web sites that point in your internet site, while internal links are hyperlinks in your own web page that factor for your different pages (at the same web page).
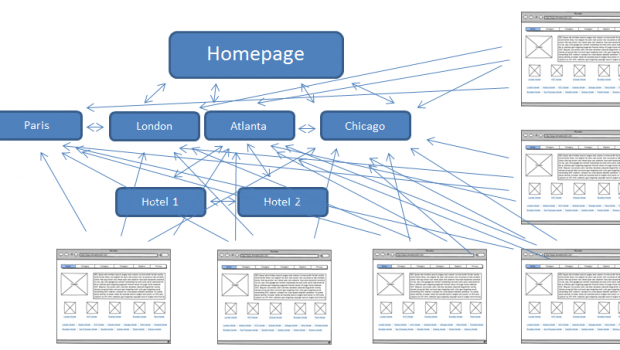
Links have historically played a big function in search engine marketing. Very early on, search engines wanted assist identifying which URLs have been greater truthful than others to assist them decide the way to rank search outcomes. Calculating the number of links pointing to any given web page helped them do that.
The role content plays in SEO
That something is content! Content is extra than simply phrases; it’s some thing meant to be ate up via searchers — there’s video content, picture content, and of course, text. If search engines like google and yahoo are solution machines, content material is the manner via which the engines deliver the ones answers.

Any time a person plays a seek, there are hundreds of viable results, so how do search engines decide which pages the searcher is going to discover precious? A large a part of figuring out where your web page will rank for a given query is how nicely the content for your page suits the question’s intent. In different phrases, does this page suit the words that have been searched and help satisfy the task the searcher turned into attempting to perform?
Because of this consciousness on user pride and task accomplishment, there’s no strict benchmarks on how long your content have to be, how commonly it have to include a key-word, or what you put in your header tags. All those can play a position in how well a web page performs in seek, but the attention should be at the customers who will be reading the content.
